Research & Projects — Md A Rahman
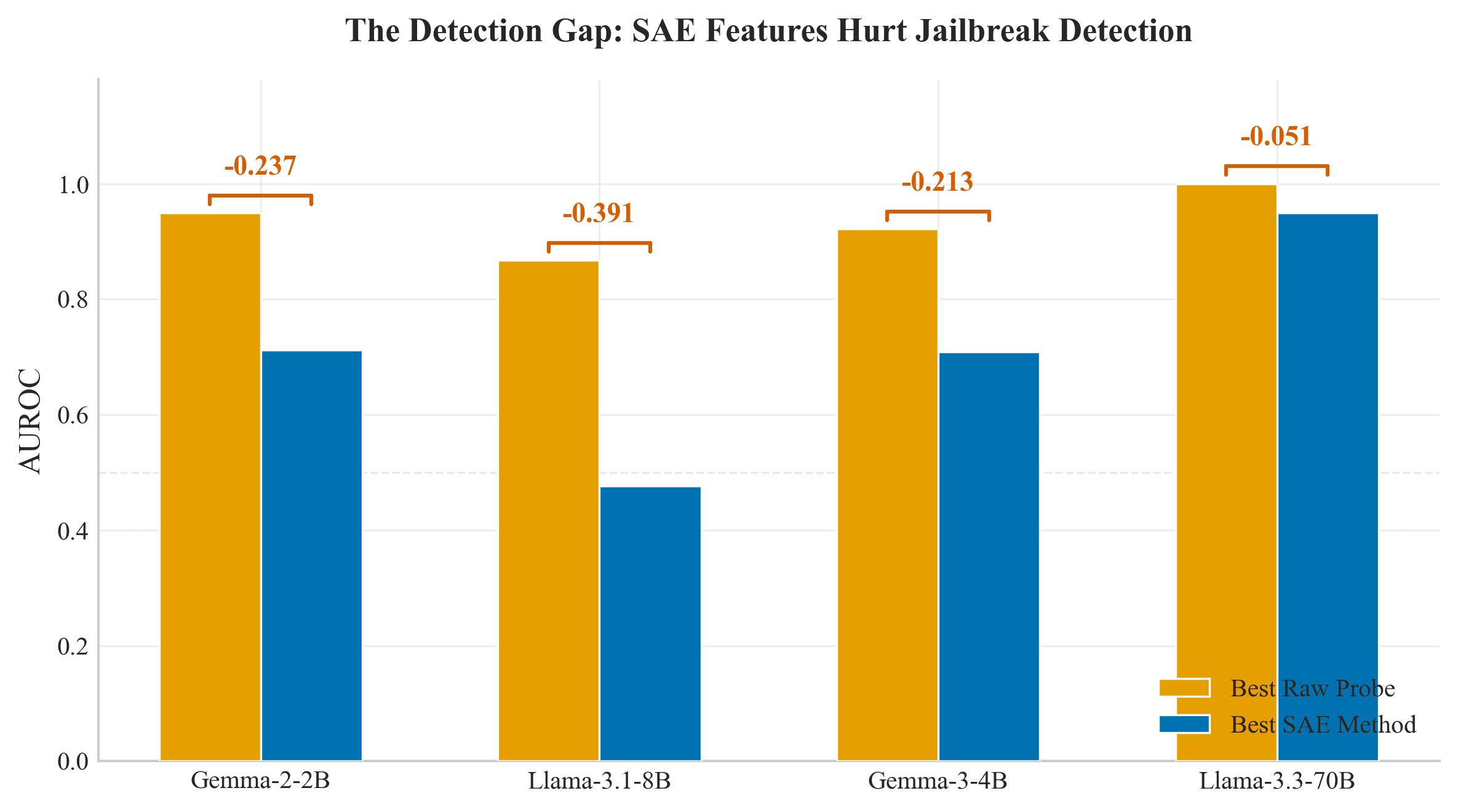
SAEGuardBench — Do SAE Features Help Detect Jailbreaks?
Benchmark comparing 8 detection methods across 4 paradigms on 6 datasets and 4 LLMs (2B-70B parameters). SAE features consistently hurt jailbreak detection compared to simple linear probes on raw activations. The Detection Gap is negative on every model tested.
Technologies: Python, PyTorch, TransformerLens, SAELens, HuggingFace, Gradio
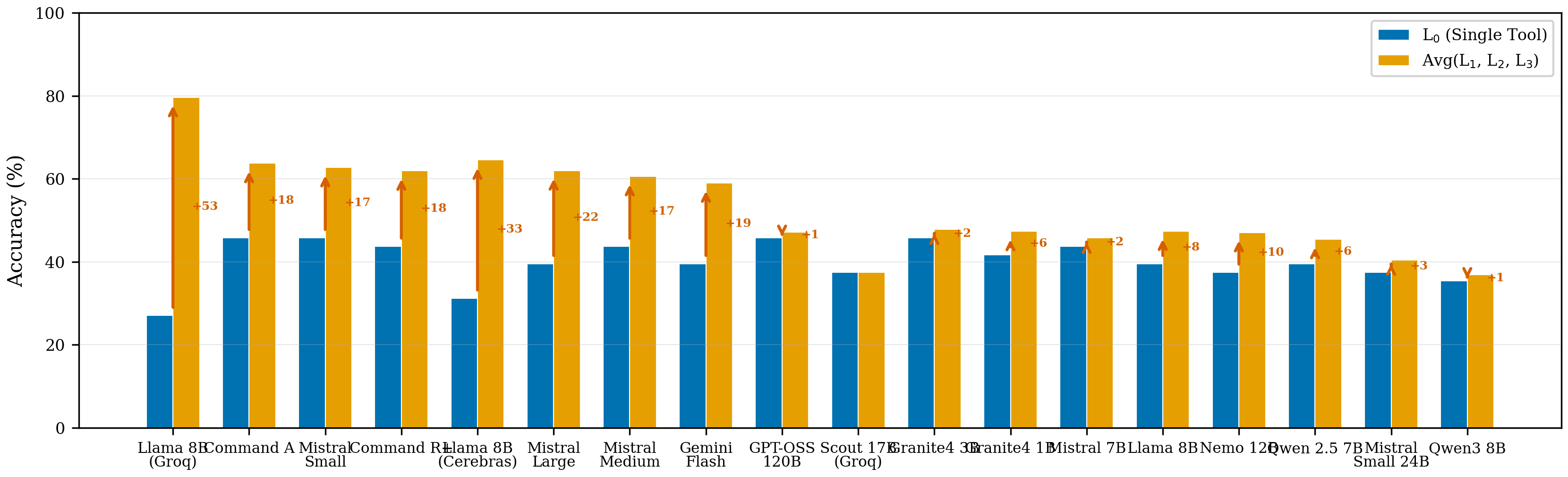
GitHubPaperCompToolBench — LLM Tool-Use Evaluation
Evaluation framework testing where 18 LLMs fail across four complexity levels of tool use. The Selection Gap: single-action selection accuracy is systematically 13.2pp lower than multi-step composition across 17/18 models.
Technologies: Python, LiteLLM, pytest, Gradio, HuggingFace
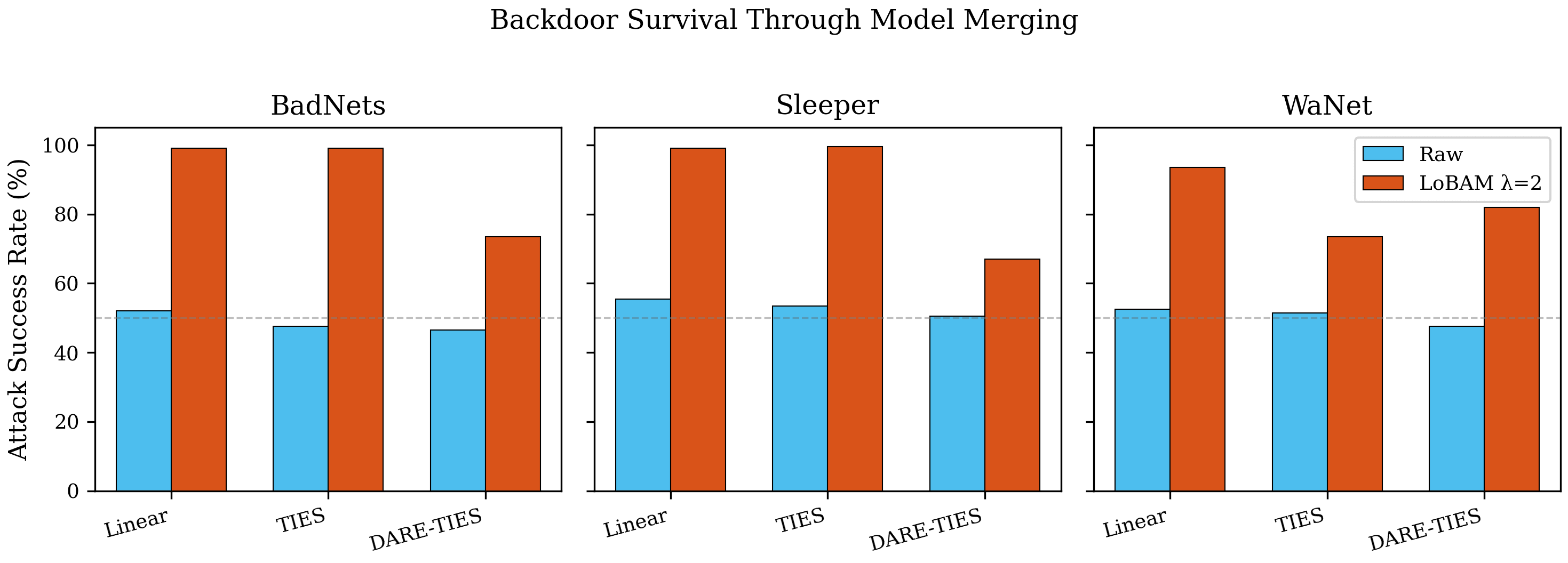
GitHubPaperMergeSafe — How Backdoors Survive Model Merging
Testing whether model merging dilutes backdoors. It does not. LoBAM brings attack success back to 83-99%. Built a three-signal pre-merge scanner with 100% recall and 0% false positives across 18 configurations.
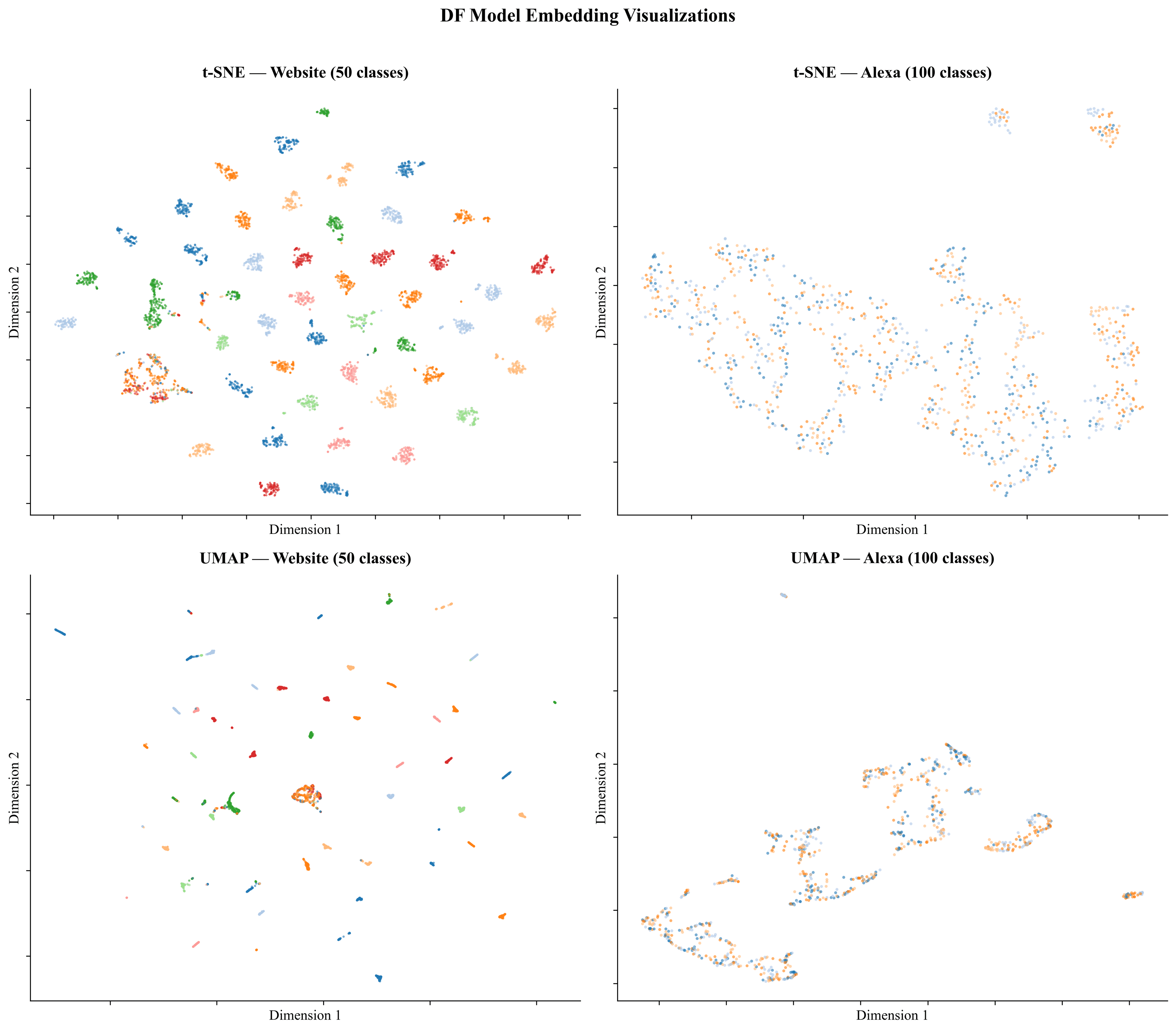
GitHubPaperTrafficLM — A 12-Year Concept Drift Study in Website Fingerprinting
Measuring how website fingerprinting models decay over time. Training 7 classifiers on 2014 Tor traffic and testing on a fresh 2026 crawl. Targeting PoPETs 2027.
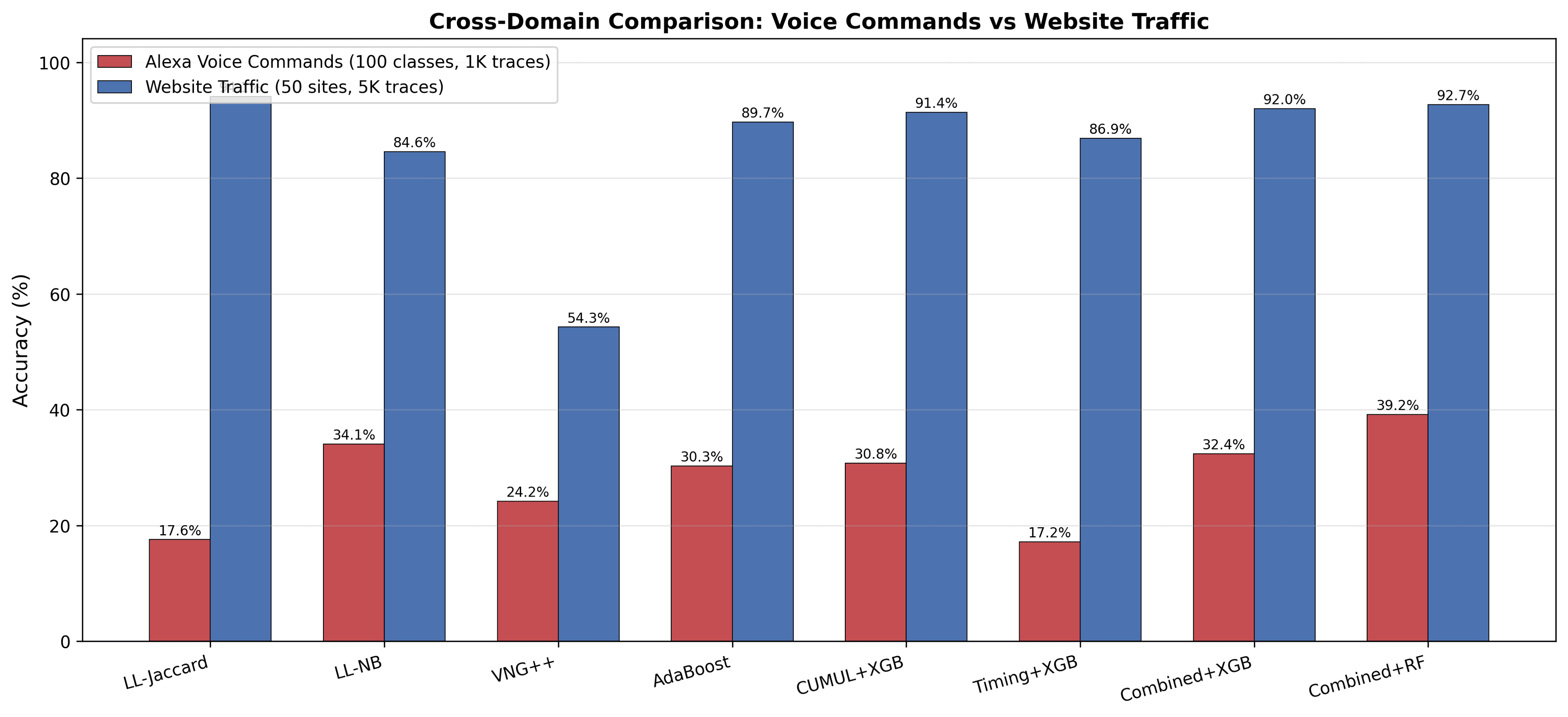
GitHubPaperTraffic Fingerprinting — Encrypted Network Traffic Classification
94.1% accuracy classifying encrypted website traffic using only packet-size features across 5,001 samples from 50 websites.
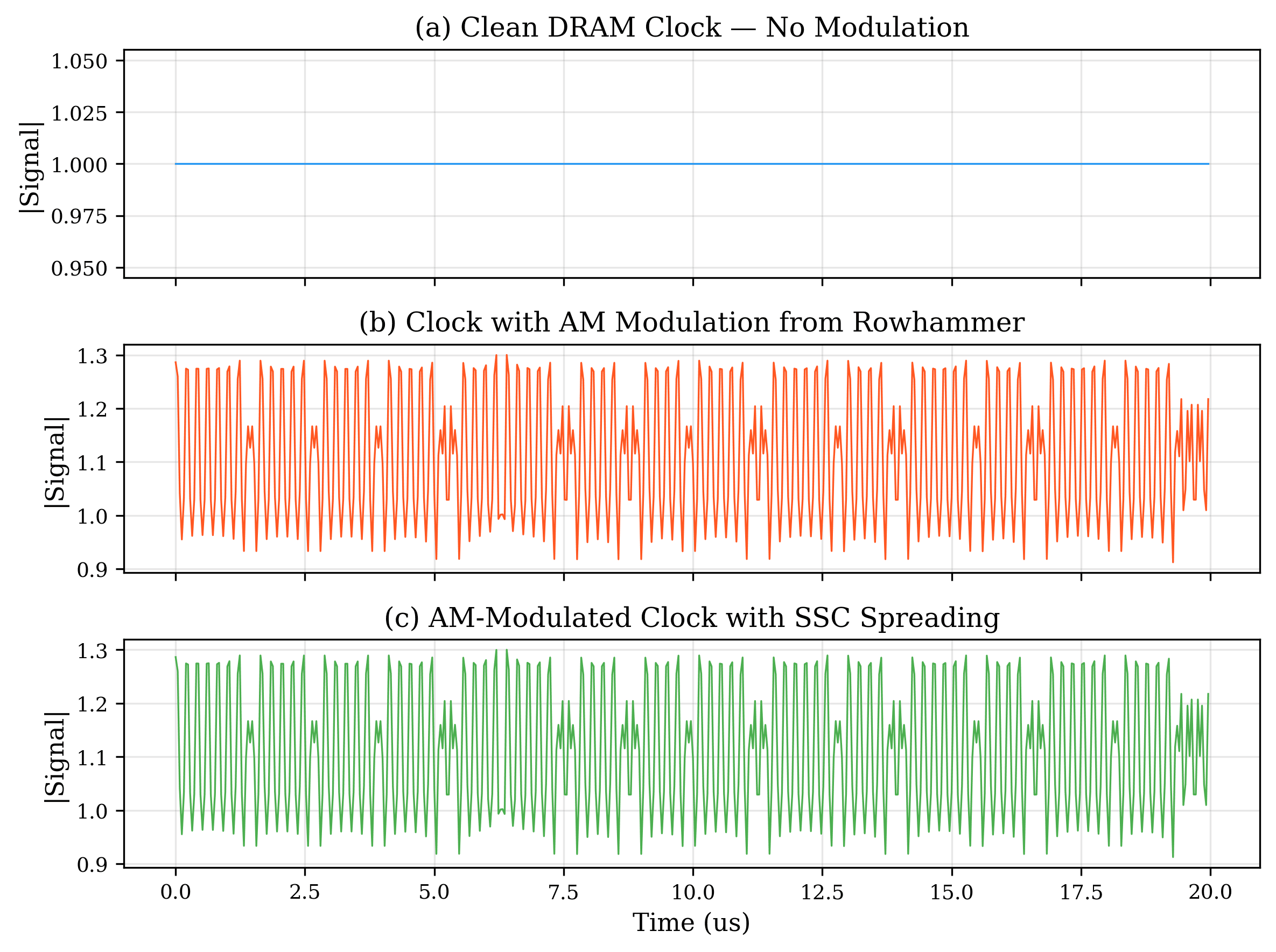
GitHubRADAR-Rowhammer — EM Side-Channel Attack Detection
EM side-channel rowhammer detection across 5 architectures, 7 attack patterns, and 3 DRAM platforms. 92.7% accuracy.
GitHubIELTSLab — Adaptive Learning Platform with Speech ML
Full-stack monorepo with 5 containerized microservices. Python ML sidecar with faster-whisper speech recognition and adaptive testing.
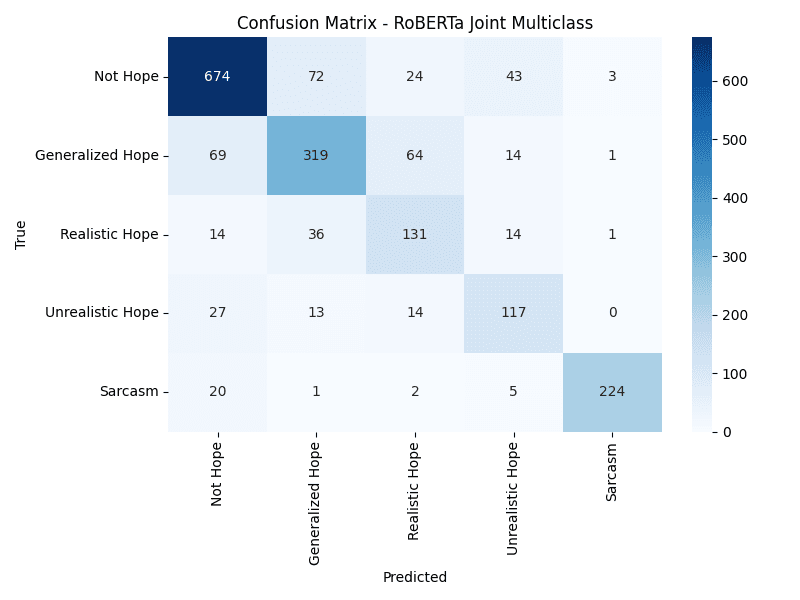
GitHubPolyHope — Hope Speech and Sarcasm Detection
Dual-task NLP framework achieving 80% F1 score using RoBERTa for hope speech detection at RaNLP 2025.
GitHub